Scrapyで作成したクローラー (スパイダー) をScrapydというクローラー管理APIを使って制御するメモです。
クローラーをバッググラウンドで動かしたい場合、cronにコマンドを登録して定期実行というのがお手軽な方法ですが、他のアプリケーションからスパイダーを起動させたり、重複起動しないように制御したい場合はちょっと大変です。
しかしScrapydを使えば、手製のアプリケーションからAPIを叩いてリアルタイムにクローラーを走らせる事も可能だし、複数あるクローラーのスケジューリングもScrapydがやってくれるので便利です。
「RockyLinux 9 + Python 3.11.0 (pyenv) + Scrapy 2.7.1 + scrapyd 1.3.0」という環境でクローラーをデーモン化するまでをやってみます。
スポンサーリンク
Scrapydのインストールと設定
Scrapydを使うために scrapyd, scrapyd-client というPythonモジュールをインストールします。
$ sudo pip install scrapyd scrapyd-client
Linuxの場合、下記順番でScrapydの設定ファイルを自動で探すので、適当な場所に設定ファイルを作成してあげます。
- /etc/scrapyd/scrapyd.conf
- /etc/scrapyd/conf.d/*
- ./scrapyd.conf
- ~/.scrapyd.conf
今回はScrapyのアプリケーションディレクトリ内でScrapydの設定ファイルを作成し運用します。
ScrapyProjectは作成したアプリケーション名なので、ここは適時変更して下さい。
$ mkdir /path/to/ScrapyProject/scrapyd $ vi /path/to/ScrapyProject/scrapyd.conf
Scrapydはこんな感じに設定します。
[scrapyd] eggs_dir = /path/to/ScrapyProject/scrapyd/eggs logs_dir = /path/to/ScrapyProject/scrapyd/logs dbs_dir = /path/to/ScrapyProject/scrapyd/dbs items_dir = jobs_to_keep = 5 max_proc = 1 max_proc_per_cpu = 4 finished_to_keep = 100 poll_interval = 5.0 bind_address = 127.0.0.1 http_port = 6800 debug = on runner = scrapyd.runner application = scrapyd.app.application launcher = scrapyd.launcher.Launcher webroot = scrapyd.website.Root [services] schedule.json = scrapyd.webservice.Schedule cancel.json = scrapyd.webservice.Cancel addversion.json = scrapyd.webservice.AddVersion listprojects.json = scrapyd.webservice.ListProjects listversions.json = scrapyd.webservice.ListVersions listspiders.json = scrapyd.webservice.ListSpiders delproject.json = scrapyd.webservice.DeleteProject delversion.json = scrapyd.webservice.DeleteVersion listjobs.json = scrapyd.webservice.ListJobs daemonstatus.json = scrapyd.webservice.DaemonStatus
max_proc はデフォルトだと 0 で無制限にクローラーを同時実行してしまうので、サーバスペックと相談していくつ同時に動かすかを設定する。
適当なディレクトリで scrapyd コマンドを実行すればScrapydが起動して 127.0.0.1:6800 でLitenしますが、設定ファイルを読み込まないで起動させるとdbsディレクトリとかをカレントディレクトリに勝手に作るので注意。
手動実行する場合は “cd /path/to/ScrapyProject ; scrapyd” とコマンドを実行すると、作成したscrapyd.confを読み込んで起動します。
scrapy.cfgの設定変更
プロジェクトディレクトリ内にあるscrapy.cfgにある[deploy]の項目を設定変更します。
[deploy] url = http://localhost:6800/ project = ScrapyProject
これでScrapydと連携できるようになります。
Scrapydのサービス登録と起動
ScrapydのデーモンはCentOS7のsystemdで管理します。
# vi /etc/systemd/system/scrapyd.service ----- scrapyd.service ----- [Unit] Description=Scrapyd daemon After=network.target [Service] WorkingDirectory=/home/miura/ScrapyProject ExecStart=/bin/bash -c '/usr/local/pyenv/versions/3.11.0/bin/python /usr/local/pyenv/versions/3.11.0/bin/scrapyd' Restart=always User=scrapy_user Group=scrapy_group [Install] WantedBy=multi-user.target
WorkingDirectoryは scrapyd.conf のあるディレクトリ、ExecStartにはPythonとscrapydのパスを書きますが、pyenvで管理するパスに適時変更。
クローラーを特定のユーザー権限で動かしたい場合は User, Group も設定しておく。
ここまで書いたらサービス登録してScrapydをバッググラウンドで起動させます。
# systemctl enable scrapyd # systemctl start scrapyd
psコマンドを実行し、Scrapydのプロセスを確認できたら起動成功です。
# ps auxw | grep scrapyd scrapy_user 30887 0.0 1.9 285892 40364 ? Ss 11:33 0:02 /usr/local/pyenv/versions/3.11.0/bin/python /usr/local/pyenv/versions/3.11.0/bin/scrapyd
Scrapyd停止と再起動はこのように実行します。
# systemctl stop scrapyd # systemctl restart scrapyd
Scrapydの管理画面にアクセスする
Scrapydは簡単な管理画面を持っていて、各クローラーのステータスや動作ログが確認できます。
デフォルトでは http://127.0.0.1:6800 で管理画面にアクセスできます。
Scrapydにジョブを登録してクローラーを走らせる
Scrapydにクローラーのジョブを管理させるにはまず scrapyd-deploy コマンドでスパイダーをデプロイします。
$ cd /path/to/ScrapyProject
$ scrapyd-deploy -p ScrapyProject
Packing version 1552571177
Deploying to project "ScrapyProject" in http://localhost:6800/addversion.json
Server response (200):
{"node_name": "myhostname", "status": "ok", "project": "ScrapyProject", "version": "1552571177", "spiders": 3}
次に curl コマンドを使ってAPIにジョブを登録します。
$ curl http://localhost:6800/schedule.json -d project=ScrapyProject -d spider=mySpider
{"node_name": "myhostname", "status": "ok", "jobid": "c2624744465f11e9ae3b9ca3ba021a29"}
上記で登録したプロジェクト名、スパイダー名と違いますが、登録後はScrapydの管理画面にこのように表示されます。
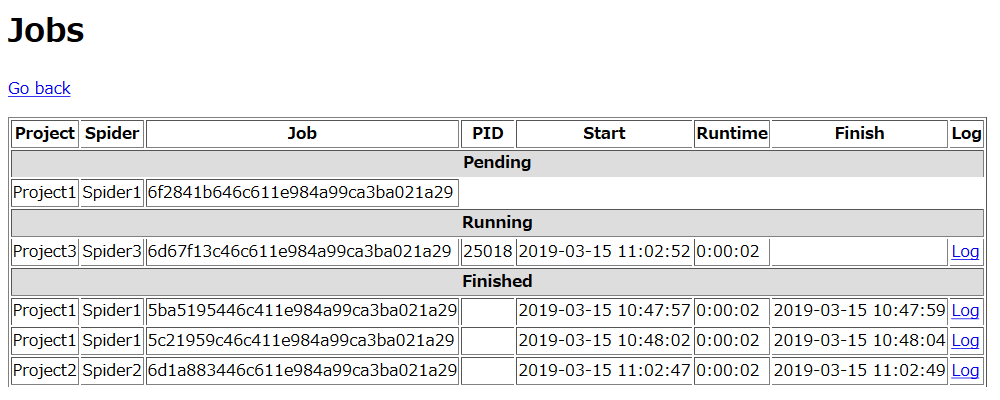
空いていれば登録したジョブは即座に実行されて、他のジョブを実行中の場合は後に登録したクローラーは待機します。
後はcronとかでAPIにジョブを定期的に登録してあげればScrapydがよしなにクローラーを実行してくれます。
max_proc_per_cpu と jobs_to_keep の設定も大事だと思いますが、設定を変えても何処に効いているのかがイマイチわかりませんでした。
何はともあれクローラーの多重起動をこれで制御できるようになったのでScrapyがますます便利になりました。
Scrapyd利用時のエラー集
Scrapydを動かした時に発生したエラーをここにまとめておきます。
TypeError: __init__() got an unexpected keyword argument ‘_job’
TypeError: __init__() got an unexpected keyword argument ‘_job’
■ 対処方法
Scrapydはジョブの実行時に _job の引数をスパイダーに渡すようで、中で __init__() を利用している場合は可変長引数 (*args, **kwargs) を付ける。
■ NG
class MySpider(scrapy.Spider):
name = 'myspider'
def __init__(self):
■ OK
class MySpider(scrapy.Spider):
name = 'myspider'
def __init__(self, *args, **kwargs):
Scrapydはこのようにクローラーを実行するので、_job にはジョブを識別できるIDが渡されるようです。
/usr/local/pyenv/versions/3.11.0/bin/python -m scrapyd.runner crawl MySpider -a _job=bb1d1820484811e9a41c9ca3ba021a29
Connection to the other side was lost in a non-clean fashion: Connection lost.
twisted.python.failure.Failure twisted.internet.error.ConnectionLost: Connection to the other side was lost in a non-clean fashion: Connection lost.
ScrapydのAPIからRunning中のクローラーのキャンセルリクエストを送ると、少し待ってログにこのエラーが出てクローラーがハングする。
$ curl http://localhost:6800/cancel.json -d project=ScrapyProject -d job=5915184246c911e996c69ca3ba021a29
正確にはクローラーは異常終了して、クローラーが呼び出したSeleniumのプロセスだったり、Scrapyd側のジョブステータスはその状態で止まりゾンビ化します。
クローラーがまだPendingであれば問題なくキャンセルできるので、もしかするとRunning中のクローラーへ使うものでは無い?
Seleniumとか他のプロセスが原因で、Scrapydからのクローズ処理が正常に走らないのかも知れない。(引き続き調べる)
とりあえずScrapydをrestartすればゾンビも消えて元には戻る。