最近、Amazonで偽レビューを使って評価を偽装した胡散臭い商品が多いですが、買い物をする時に邪魔でしかないのでこれを機械学習 (ランダムフォレスト) で見抜けないか試してみました。
機械学習について勉強する中で、何か実践的なデータでやってみたいと思って試してみたら、まぁまぁ上手くいってそうなのでやった事と作ったモデルをこの記事に残しておきます。
用語とかアルゴリズムとか理解出来てない部分は多いですが、Python を理解していて機械学習にちょっと興味がある人向けに書いています。
この記事の全体はこんな流れなので興味がある方は是非どうぞ。
- 機械学習の環境構築
- データ収集と特徴の選択
- 機械学習と精度のテスト
- モデルの可視化
- 作成したモデルの使い方例
- 考察:Amazonの偽レビューの実態
スポンサーリンク
機械学習に必要なもの
まずはじめは機械学習に必要な環境、データについて簡単に説明します。
環境構築
Pyenv を使い CentOS7 上に機械学習の環境を構築します。
必要なライブラリは pip install でインストールしておきます。
- Python 3.7.2
- jupyter
- matplotlib
- pandas
- scikit-learn
エディタは Jupyter Notebook が便利らしいという事だったのでこれもインストールし、ファイアウォールで TCP:8888 番を開けるか、リバースプロキシ何かを使うと良いと思います。
準備が完了した後は下記のように初期設定をして Jupyter Notebook を起動します。
## コンフィグの雛形を作る $ jupyter notebook --generate-config Writing default config to: /home/miura/.jupyter/jupyter_notebook_config.py ## パスワードの設定 $ python -c 'from notebook.auth import passwd;print(passwd())' Enter password: Verify password: sha1:a041ac704b7c:5a6988ead60a4d97eeef2709134f4e5e3c0c3dd6 <- コピーしておく ## 設定 $ vi ~/.jupyter/jupyter_notebook_config.py c.NotebookApp.ip = '0.0.0.0' c.NotebookApp.open_browser = False c.NotebookApp.port = 8888 c.NotebookApp.password = 'sha1:a041ac704b7c:5a6988ead60a4d97eeef2709134f4e5e3c0c3dd6' ## 起動 (Ctl + C で終了) $ jupyter notebook
特徴選択とデータ収集
機械学習をするには覚えさせるためのデータが必要ですが、これは自力で Amazon より収集して前処理というものを行っておきます。
人間が偽レビューを見分ける方法はいくつかありますが、その中でも機械学習に使いやすいように数値化できる特徴を絞りそのデータを集めます。
- 販売期間 (日数)
- 販売元 (Amazonの場合は1、それ以外は0)
- レビューの総数
- 星の平均点
- 販売価格
- 割引しているかどうか (割引は1、それ以外は0)
- 星1 – 5の数
これらの特徴を元に本物のレビューデータは 0、偽レビューデータは 1 として正解ラベルを付けていきます。
著作権が問題になるので集めたデータは公開する事が出来ないのですが、集めたデータ総数は 822 商品で本物と偽レビューの割合は半々くらいです。
データはこのようなフォーマットの CSV ファイルに保存しました。
sale_period,marchant_flag,review_count,rating_total,product_price,price_saving,rating_5,rating_4,rating_3,rating_2,rating_1,train "144","0","84","4.7","2980","1","87","8","5","0","0","1" "158","0","283","4.3","3699","1","72","11","3","4","10","0" "40","0","455","4.0","4999","1","51","28","8","4","9","1"
データを集めてラベル付けをする作業が一番大変ですが、集めてしまえばあとは簡単なので頑張ります。
また、データ総数はもっと用意した方がいいとは思います。(大変なので今回は途中で諦めた…)
Amazonの偽レビューを学習させる
データが集まったら次は機械学習です。
Jupyter Notebook を使いコードを入力して確認しながら進めていきます。
まずは集めたデータ (CSV) を pandas で読み込み、訓練データとテストデータに分割します。
import pandas as pd
from sklearn.model_selection import train_test_split
df = pd.read_csv('amazon.csv')
train_X = df.drop('train', axis=1)
train_y = df.train
(train_X, test_X ,train_y, test_y) = train_test_split(train_X, train_y, test_size = 0.3, random_state = 666)
次はランダムフォレストで機械学習をし完成したモデルの性能評価を行います。
from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import (roc_curve, auc, accuracy_score) clf = RandomForestClassifier(random_state=0, criterion="entropy",n_estimators = 100) clf = clf.fit(train_X, train_y) pred = clf.predict(test_X) fpr, tpr, thresholds = roc_curve(test_y, pred, pos_label=1) auc(fpr, tpr) 0.9426536239495799 accuracy_score(pred, test_y) 0.9433198380566802
AUC はモデルの性能指標 (1に近づくほど高評価) で、accuracy_score はテストデータでの正解率を表します。
どちらも 0.94 なら中々うまくいったのではないでしょうか。
特徴の重要度を可視化する
数値だけではあれですので、偽レビューは何の特徴が決め手になっているのかを可視化してみます。
import numpy as np import matplotlib.pyplot as plt %matplotlib inline features = train_X.columns importances = clf.feature_importances_ indices = np.argsort(importances) plt.figure(figsize=(6,6)) plt.barh(range(len(indices)), importances[indices], color='b', align='center') plt.yticks(range(len(indices)), features[indices]) plt.show()
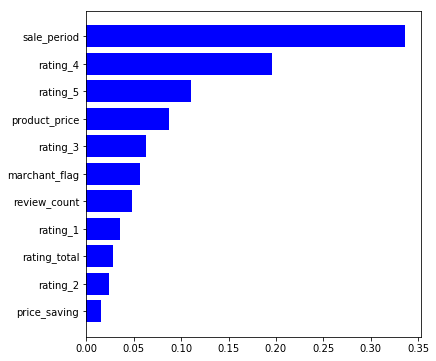
販売期間が最も重要な特徴量らしく、次に星4の数。そして星5の数と販売価格がまずまず重要なようです。
偽レビューを集めてまで売ろうとする商品はチープな物が多いせいか、ボロが出る前に売り抜けようとするみたいです。数ヶ月前に買った中国製品の履歴を見たらもう無いとか結構あります。
また、偽レビューは星5でばっかり集めるのでどうしても星のヒストグラムの形が不自然になります。名だたる企業の製品で売れ筋の商品とかと比べると一目瞭然です。
あとは、偽レビューは主に購入後の全額返金という形で集めてるので、お手頃価格な商品じゃないとレビューが集まりにくいようです。なので、商品の価格帯も重要みたいです。
これらの事情を考えるとこのモデルが重要視している特徴は納得がいきます。
モデルの保存と組み込み方
結構良いモデルが出来たと思うので保存して再利用できるようにしておきます。
保存する時はこのように。
from sklearn.externals import joblib joblib.dump(clf, 'amazon.pkl')
使う時はこのように読み込みます。
clf = joblib.load('amazon.pkl');
## 判定する
pred = clf.predict([data])
print(pred)
今回作成したモデルは下記よりダウンロードできます。
スクリプトにモデルを組み込む例
Amazon はスクレイピング禁止なので動かしちゃだめですけど、便宜上、必要なデータ (特徴) の抽出方法を BeautifulSoup で書いたスクリプトがこれになります。
BeautifulSoup の抽出処理を書き直して、PC のブラウザを Selenium で操ってあげればいいんじゃないかなとは思ってます。
import re
import pandas as pd
import requests
import time
import datetime
import traceback
from bs4 import BeautifulSoup
from sklearn.ensemble import RandomForestClassifier
from sklearn.externals import joblib
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.96 Safari/537.36'
}
def get_product(url):
data = {
'sale_period': 0,
'marchant_flag': 0,
'review_count': 0,
'rating_total': 0,
'product_price': 0,
'price_saving': 0,
'rating_5': 0,
'rating_4': 0,
'rating_3': 0,
'rating_2': 0,
'rating_1': 0
}
try:
res = requests.get(url, headers=headers)
soup = BeautifulSoup(res.content, features='lxml')
first_date = soup.select('.date-first-available .value')
if first_date:
first_date = first_date[0].text
else:
first_date = soup.select('#detail_bullets_id')[0]
first_date = re.search(r"取り扱い開始日:\s(\d{4}\/\d{1,2}\/\d{1,2})", first_date.text)
first_date= first_date.group(1)
review_count = soup.select('#acrCustomerReviewText')[0].string.replace('件のカスタマーレビュー', '')
data['review_count'] = review_count.replace(',', '')
data['rating_total'] = soup.select('.arp-rating-out-of-text.a-color-base')[0].string.replace('5つ星のうち', '')
product_price = soup.select('#priceblock_ourprice')[0].text
data['product_price'] = re.sub(r'(¥|\s|,)', '', product_price)
rating_info = soup.select('.cr-widget-Histogram')
rating_info = rating_info[0].select('.a-text-right.aok-nowrap')
## rating
for i in range(5):
rating_no = str(5 - i)
rating = rating_info[i].find('a')
if rating:
data['rating_' + rating_no] = rating.string.replace('%', '')
else:
data['rating_' + rating_no] = 0
merchant_info = soup.select('#merchant-info')[0].text.strip()
marchant_flag = re.search('Amazon.co.jp が販売、発送します。', merchant_info)
if marchant_flag:
data['marchant_flag'] = 1
else:
data['marchant_flag'] = 0
price_saving = soup.select('#regularprice_savings')
if price_saving:
data['price_saving'] = 1
else:
data['price_saving'] = 0
## date calc
now = datetime.datetime.now()
start = first_date.split('/')
start = datetime.date(int(start[0]), int(start[1]), int(start[2]))
end = datetime.date(now.year, now.month, now.day)
data['sale_period'] = (end - start).days
except:
print(res)
traceback.print_exc()
return data
if __name__ == '__main__':
url = '商品ページのURL'
clf = joblib.load('amazon.pkl');
product_data = get_product(url)
df = pd.Series(product_data)
pred = clf.predict([df])
print(df)
print(pred)
先程作ったモデルに新しいデータを渡してあげると本物なら 0、偽レビューの可能性が高いなら 1 を返します。
■ 本物
sale_period 4311 marchant_flag 1 review_count 3787 rating_total 3.9 product_price 782 price_saving 0 rating_5 48 rating_4 26 rating_3 12 rating_2 7 rating_1 7 dtype: object [0]
■ 偽レビュー (の可能性が高い場合)
sale_period 167 marchant_flag 0 review_count 2514 rating_total 4.3 product_price 6680 price_saving 1 rating_5 65 rating_4 22 rating_3 5 rating_2 2 rating_1 6 dtype: object [1]
100% では無いものの、中々いい精度で判定しているように見えます。Amazon の偽レビューを見分ける事は機械学習で十分できそうですね。
念の為書きますが、このモデルでは商品の善し悪しまでは判断してないのでその点はご了承ください。
機械学習については以上ですが、Amazon の偽レビューについてはもう少し書きます。
Amazonの偽レビューはどのように募集しているのか?
Amazon の偽レビューの多くは中国の出店者が、お金を支払う事で日本人等にレビューを書かせているケースが多いようです。
Amazon では購入者じゃないとレビューが書けなくなったので一度その商品を買ってもらい、あとで高いレビューと引き換えに PayPal 等で返金を行うというのが主な流れです。
Amazon のプロフィールデータを通じた直接依頼が多いようですが、他にも SNS 等で堂々と募集しているのがすぐに見つかります。
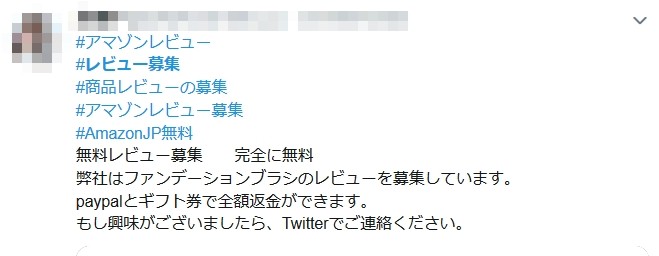
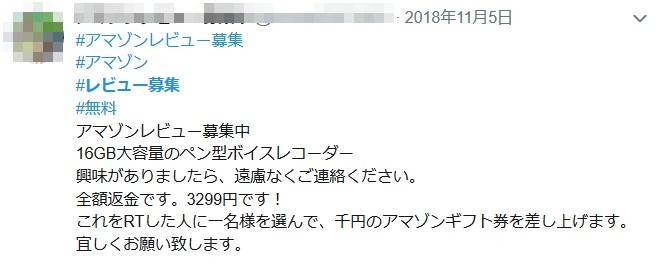


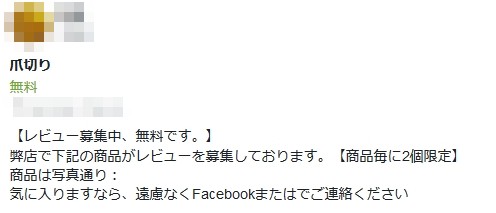
何でも日本人はショップの信頼性ではなくレビューが高い商品を買うという販売ノウハウが中国で出回っているようで、完全にカモにされているような気がします。
ただ自分もショップを最初から疑って見たりはしないので成る程とは思いました。
爪切り一つにまでこうやって偽レビューを募集している状況なので、今の Amazon のレビューってかなり信用出来ない物となっている気がします。
Amazonの偽レビュアーは日本人も多い
機械学習用にデータを集めている時に気付きましたが、偽レビューを書いているのは日本人が多いみたいです。
たまーに、日本語が怪しいレビューもありますが殆どは文章だけでは判断しにくいレベルでした。
偽レビューバイトで商品を無料入手してメルカリ等で売る、無在庫転売の副業ノウハウも出回っているいるようなのでこういうのに加担する日本人が多いという事でしょうか。
Amazon 公認レビュアー? の Vien 先取りプログラムでも怪しい人はいるし、レビュアーランキングに入っている人も平気で偽レビューを書いていたりしますので信用ならないです。
最初はスパム判定で定評のあるナイーブベイズでレビュー本文を判断とも考えましたが、日本人が作文してるならちょっと難しいかもと思い止めました。
レビューで高評価の商品は本当に売れるのか?
次にここまで必死に集める高評価の偽レビューはそもそもマーケティング効果があるのか?について考えます。
実はこれ非常に有用という事は自分も経験済みで、Amazon じゃないですが高評価のレビューを集めた事があります。
その時はレビューをしてくれたら特典プレゼント!みたいに募集をしてみたのですが、ちょっとした事でもユーザーにメリットを与える事で悪いレビューは付かなくなりますし、レビューの数も格段に増えます。
何も無いとよほどのファンか辛口レビューしか付きませんが、ちょっとの差で高評価レビューが簡単に集まりそれを見て買ってくれる人も多いので販売数も伸びます。
恐るべし偽レビュー効果です。
まとめ
Amazon の偽レビューを判定するモデルは機械学習の勉強がてらやってみましたが、特徴の選択方法とかどんなデータを集めたら良いかとかがわかってきた感じがします。
scikit-learn を使えば機械学習自体は難しくないですが、やっぱり一番大変なのはデータ集めとラベル付けですね。
折角モデルを作ったのでブラウザに組み込んで使えたらなと思ってますが、そのスキルが無いのが残念…
機械学習は畑違いな分野ですが、自分でモデルを構築して Web とかに組み込めたら面白い事がもっとできそうなので久しぶりにワクワクしています。
また、今回は書きのページが非常に参考になりました。
機械学習はオライリーの本を買って読んだりもしましたが、やっぱり手を動かすのが一番理解できますね。